A CEO tells her department heads she wants 10 agentic AI deployments every month. Every department. Infrastructure, finance, marketing, operations. No problem statement attached. No budget allocated. No success criteria defined. Just a number, cascaded down from a conference keynote or a vendor demo.
We see versions of this directive across industries. The details change. The structure is always the same. A deployment count becomes the target. Visible adoption becomes the goal. Usefulness becomes optional. The resulting metrics are KPIs in name only. They are not Key, and they do not Indicate Performance.
The forces behind these mandates are predictable. Vendor demos promise capabilities that sound transformational. Other executives at industry events describe their own AI successes, and a meaningful share of those descriptions are inflated or outright fictional. A CEO hears that a competitor deployed 50 AI agents across their operations and assumes the path to competitiveness runs through matching that number. The benchmarking ignores a critical variable. The competitor may have thousands of data scientists, billions of transactions per year, and a decade of data infrastructure investment. A 50-person company with 5 data engineers operating in a completely different industry cannot replicate that outcome by mandate.
Fig 1. Mandate vs Strategy Spectrum – Deployment count mandates on one end, outcome driven strategy on the other.
Klarna offers the most public example. The company announced in early 2024 that its AI assistant was doing the work of 700 customer service agents, froze hiring for more than a year, and made AI first a banner the CEO carried through the company’s pre IPO publicity cycle. By May 2025 it was rehiring humans, with the CEO conceding that the cost first approach had produced lower quality service. The mandate came first. The reckoning with what the AI could actually sustain came later.
Commonwealth Bank of Australia followed a similar arc on a shorter timeline. In mid 2025 it cut 45 customer service roles, citing a new voice bot that it said had reduced call volumes by 2,000 per week. Within weeks the bank admitted the roles were not redundant, that call volumes had risen rather than fallen, and that staff were working overtime to cover the gap. It apologized and reinstated the positions. The technology was announced as a workforce decision before anyone confirmed it could carry the load.
This is not new. The enterprise technology hype cycle has repeated itself with SMP clustering in the early 2000s, VMware in the late 2000s, cloud in the 2010s, serverless and everything as a service in the early 2020s, and now agentic AI. Each wave followed the same progression. Executives mandated adoption, teams scrambled to comply, and the organizations that extracted real value were the ones that matched the technology to a defined business problem.
Technology that delivers genuine value does not need to be forced on every department.
Gartner’s 2026 Hype Cycle for Agentic AI places agentic AI at the Peak of Inflated Expectations. More than 60% of organizations expect to deploy agents within two years.
You Are Measuring the Wrong Thing
Think about how you evaluate a self driving car. You do not measure its success by how fast it goes. You watch how it drives. How it handles unexpected obstacles. How it corrects when conditions change. Whether it knows when to hand control back to the human. The speedometer is a data point. The driving behavior is the performance indicator.
Fig 2. The Self Driving Car Analogy – Judge an agent on its driving behavior, not its speedometer.
Agentic AI measurement works the same way. Most organizations track three things.
Latency. How fast the agent responds.
Accuracy. How often the agent gets the right answer.
Task count. How many tasks the agent processed.
These are the speedometer. They tell you the system is running. They do not tell you whether the system is producing business value, whether users trust it, or whether the decisions it makes are sound.
The measurement reframe starts with a fundamental question about what agents actually do. The most valuable agents function as decision offloaders. The real value they deliver is a reduction in the number of things a human has to notice, choose, or remember every day.
Picture your VP of Customer Success on a Monday morning. She opens her laptop to 80 unresolved tickets from the weekend. Before she can think about the three escalations that actually need her judgment, she spends 45 minutes triaging the queue, routing tickets to the right teams, drafting templated responses, checking which SLAs are approaching breach, and flagging stale items for followup. She does this again on Tuesday. And Wednesday. By Thursday afternoon, the mental fatigue from hundreds of small, repetitive judgment calls has eroded her capacity for the strategic work she was hired to do. None of those individual decisions are difficult. Together they consume the week.
Fig 3. The Monday Morning Queue – Hundreds of small, repetitive judgment calls erode capacity for the strategic work.
When an agent absorbs that decision load and makes consistently acceptable calls on the routine items, the value shows up as mental quiet. The manager’s calendar opens up for the complex cases that require genuine judgment. Time and cost savings follow as byproducts, but they are not the primary design target.
A system that responds instantly but still requires the human to review, approve, or second guess every output has not offloaded anything meaningful. A slightly slower system that closes loops, eliminates followup tasks, and removes decisions from the human’s plate is more valuable by every measure that matters to the person using it.
This reframe changes how you run sprints. The agile process becomes a cycle of identifying the next batch of decisions the agent can absorb, measuring whether those decisions are being made at an acceptable quality, and mapping the cognitive load reduction to cost and time savings for the business case.
But measurement only works when the task is defined first. If you cannot describe in one sentence what the agent is supposed to accomplish, no measurement framework will save you.
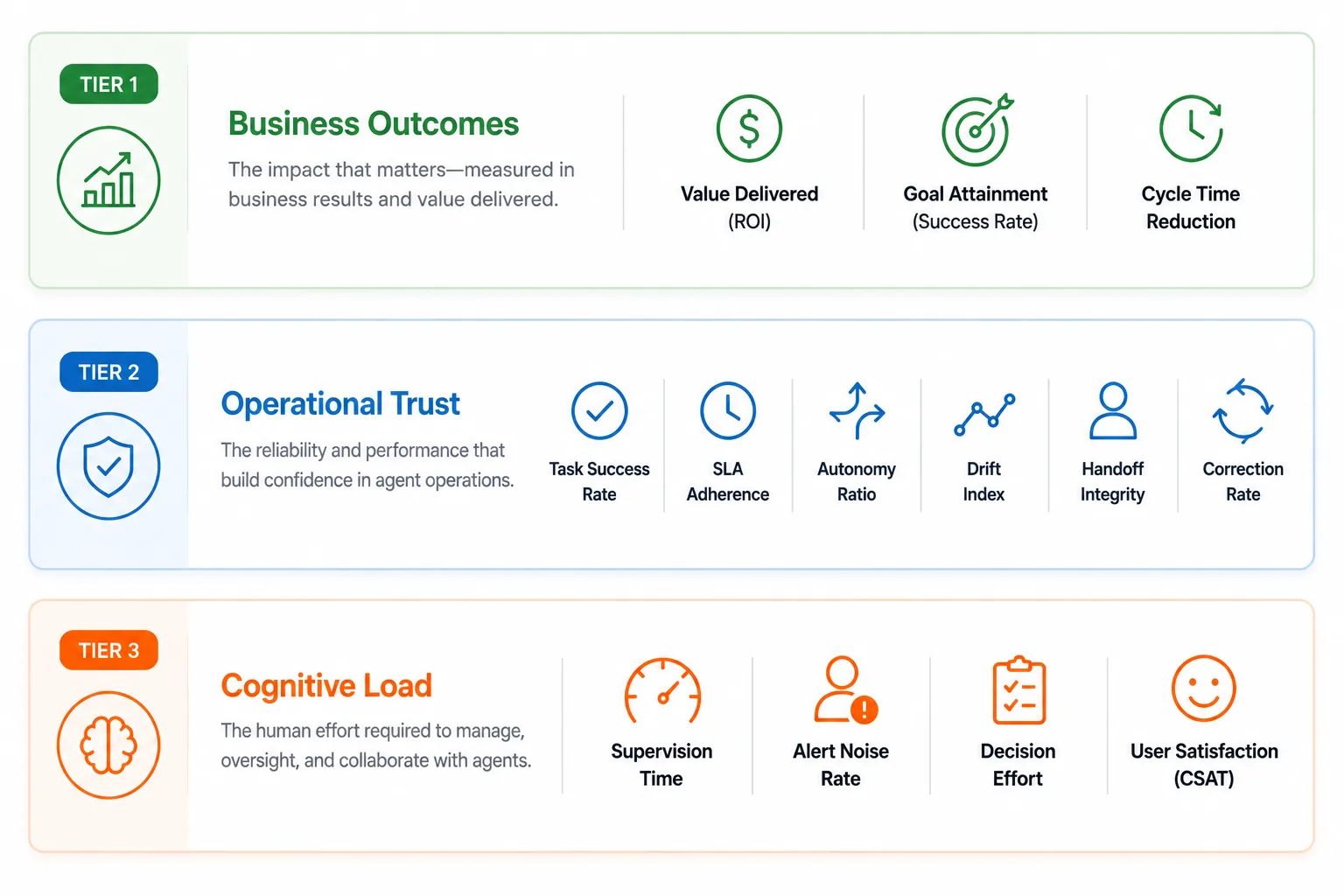
Three tiers of agent measurement
The measurement framework that works in production organizes KPIs into three tiers.
Tier 1 captures whether the agent is producing business results.
Tier 2 captures whether the agent is reliable enough to expand.
Tier 3 captures the value that traditional frameworks miss entirely, the cognitive load the agent removes from the humans who use it.
Fig 4. The Three Tier Measurement Framework – Business outcomes, operational trust, and cognitive load.
Tier 1. Business Outcomes. These metrics justify continued investment. They answer one question. Did the agent produce a result the business cares about.
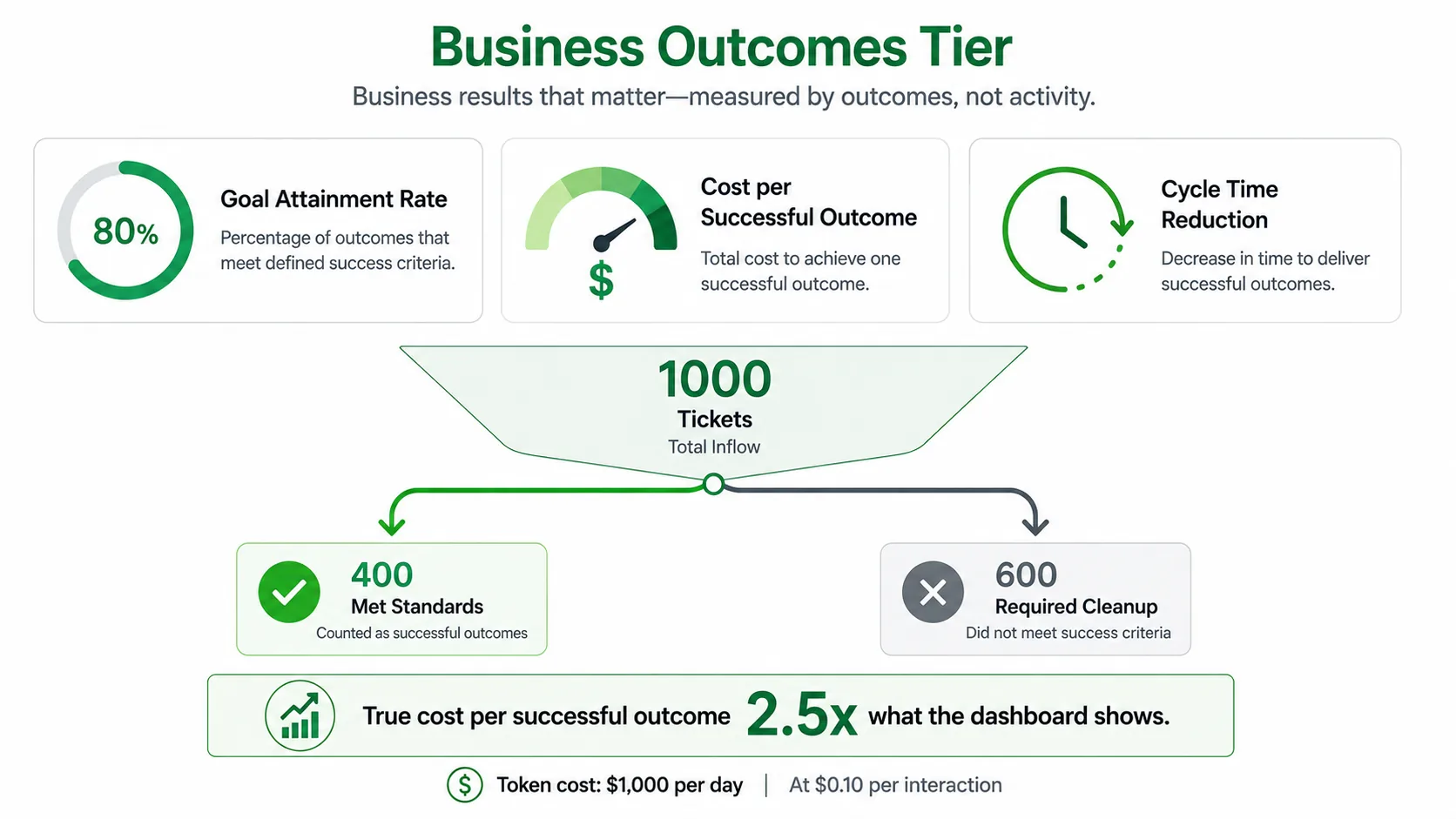
Goal attainment rate. How often the agent accomplishes the task it was assigned to the defined acceptance criteria. Attempted tasks that did not meet the standard do not count.
Cost per successful outcome. Total cost (tokens, compute, human review time, error correction) divided by outcomes that met the standard. If an agent processes 1,000 tickets but only 400 meet quality standards, the true cost per outcome is 2.5x what the dashboard suggests. Token costs compound quickly. At 10 cents per interaction, an agent fielding 10,000 queries per day runs $1,000 daily in inference alone.
Cycle time reduction. The full end to end process time, including downstream rework and human review. If the agent is fast but creates downstream rework, cycle time may not improve.
Fig 5. Tier 1 — Business Outcomes – Vanity metrics quietly mask the true cost per successful outcome.
Tier 2. Operational Trust. These metrics tell you whether the agent is safe to expand. They are the difference between an agent that works in a demo and an agent that survives its first quarter in production.
Human intervention rate. How often a human overrides, corrects, or completes the agent’s work. The single most important operational signal. If people keep overriding the agent, it has not earned the right to operate independently. Track the trend. A declining rate signals earned trust.
Autonomy ratio. The proportion of the workflow the agent handles without human involvement.
Drift index. How far the agent’s output quality has moved from its initial performance. Model drift, data drift, and prompt decay all degrade quality over time. A system that worked in month one can fail silently in month four without drift monitoring.
Guardrail violations. How often the agent breaks policy, safety, or brand rules.
Handoff integrity. Whether context survives when work passes between sub agents or between an agent and a human. Dropped context is the most common failure in multi agent systems.
Context chain health. The full trace of every interaction. Every input, reasoning step, tool call, and output. Check for dropped context, misfires, or gaps between what one sub agent passed and what the next one received.
Fig 6. Tier 2 — Operational Trust – Six signals separate a demo agent from one that survives production.
Tier 3. Cognitive Load. These metrics capture the value that traditional frameworks miss entirely. They measure what the humans using the system actually feel.
Decision surface area reduction. How many things the human no longer has to notice, choose, or remember. This is the metric that explains why users prefer certain agent systems despite those systems showing no improvement on traditional cost or time benchmarks.
Repeat usage. Whether the intended users actually return to the agent. A deployed agent that nobody trusts is worse than no agent, because it consumed resources and produced nothing.
Time to confident action. The elapsed time between a human receiving information and making a decision. Agents that synthesize and present information well reduce this time. Agents that present unreliable information increase it.
Abstention quality. Whether the agent knows when not to act. An agent that correctly declines tasks outside its competence is more trustworthy than one that attempts everything and fails on the edge cases. The ability to say “this one needs a human” is a feature.
Fig 7. Tier 3 — Cognitive Load – The value traditional frameworks miss: decisions removed from the human.
Every metric must have an owner who is accountable for it, a threshold that triggers action, and a defined action that executes when the threshold is hit. A metric that can sit on a dashboard without triggering a decision is decoration, not a KPI.
Start from What You Already Run
Most agentic AI strategy guides assume you are starting from a blank canvas. You are probably not. Every company running CRM, ERP, marketing automation, support ticketing, or accounting software already has the raw material for agentic AI. The question is which parts of that material are ready for an agent.
Amazon’s prescriptive guidance on agentic AI economics makes this explicit. Use your existing cost baseline as the starting point. Do not build a new one. You already know what your processes cost in human time and system spend. That baseline is the benchmark against which every agent deployment should be measured.
McKinsey’s April 2026 analysis reinforces the same approach. Modernize existing platforms to support interoperability and governance. Do not replace them wholesale. The strongest organizations build modular, evolutionary architectures with components that can be upgraded as technologies mature.
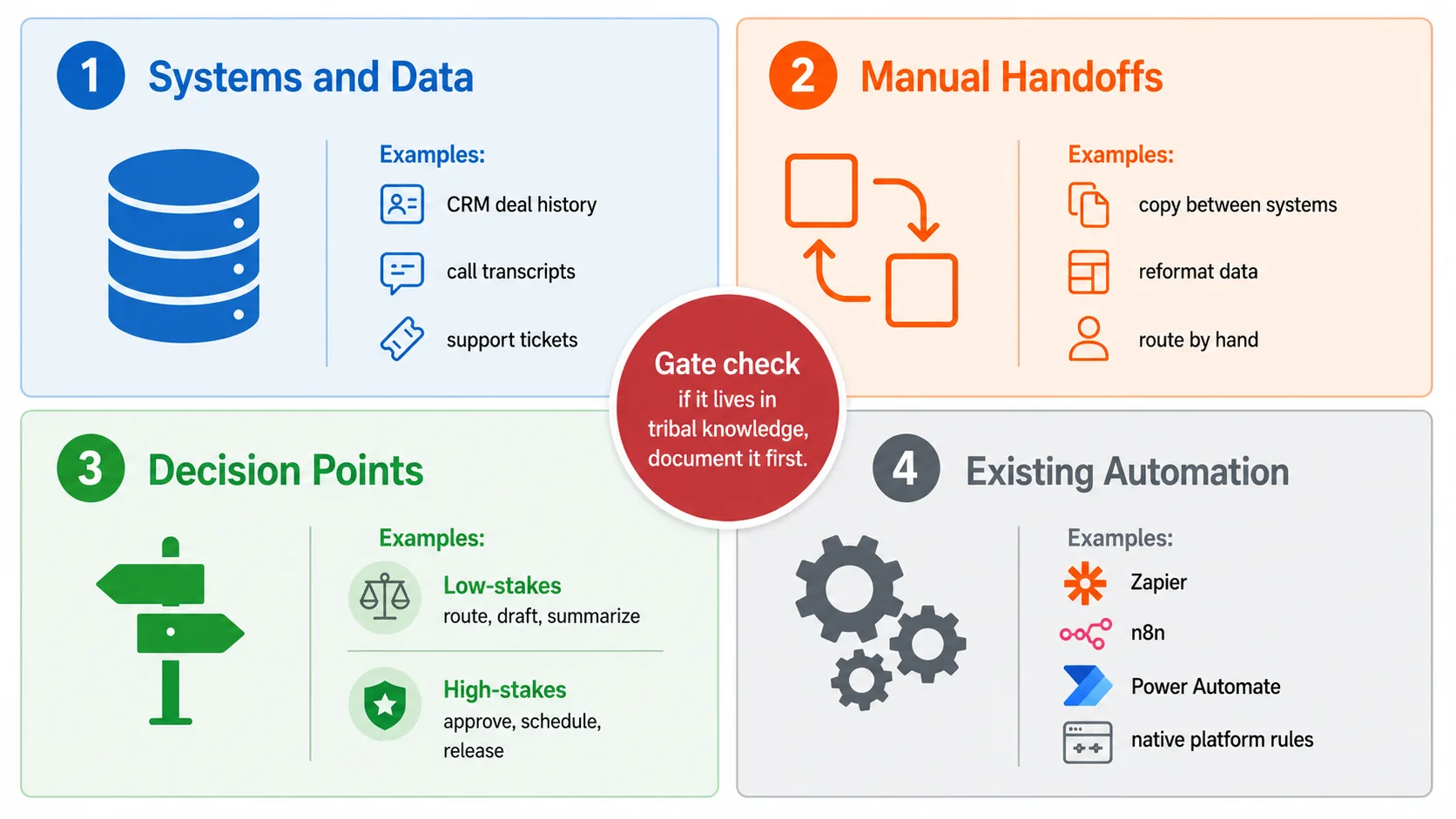
An agent readiness audit covers four areas.
1. Systems and data. Map every system that touches the workflow you are considering. Where does data originate, where does it move, and where does it get stuck. A HubSpot or Salesforce instance with 3 years of deal history, call transcripts, and support tickets is a richer foundation than a greenfield AI project with clean data and no context.
2. Manual handoffs. Identify every point where a human manually moves information between systems, reformats data, or makes a routing decision. These are your highest value targets. An insurance agency spending 15 minutes per claim copying data between intake forms and their AMS is a stronger agent candidate than a process that already runs through API integrations.
3. Decision points. Map every place where a human makes a judgment call. Separate those into low stakes decisions where a wrong answer is correctable (routing a support ticket, drafting a followup email, summarizing a meeting) and high stakes decisions where a wrong answer carries financial, legal, or safety consequences (approving a loan, changing a production schedule, releasing a compliance report). Agents should start with the first group.
4. Existing automation. Many organizations already run workflows through Zapier, n8n, Power Automate, or native platform rules. These are not agents. But they represent processes that are already defined, already have data flows, and already produce measurable outputs. Adding an AI component to an existing automation is a faster path to production than building from scratch.
Fig 8. Agent Readiness Inventory – Four areas to audit before any agent, with a documentation gate at the center.
There is a gate check before any of this proceeds. If the process lives in people’s heads, in tribal knowledge that has never been written down, you are not ready for an agent. The agent needs defined inputs, defined outputs, and defined success criteria. Tribal knowledge has none of those. Document the process first. Then automate it.
Fig 9. Systems Design Lifecycle – A hard gate: are the processes documented before you build?
Here is the counterintuitive finding. Companies with less optimized processes often get better results from AI agents than companies with highly efficient operations. When core business processes are manual, inconsistent, and poorly documented, the room for improvement is enormous. A mid market company with messy handoffs between sales, onboarding, and support has more “agentifiable surface” than a tech company that has already automated most of its workflows. Your operational inefficiency is your opportunity here.
One more thing. Before you evaluate new AI vendors, check the tools you already pay for. Firewalls, CRM platforms, ITSM tools, monitoring systems, and ERP platforms have been adding AI capabilities for years. Your existing vendor list may already cover several of the agent use cases leadership is asking for. Those features are already integrated, already licensed, and already compliant with your security posture.
One Agent, One Workflow, One Outcome
If you cannot describe in one sentence what the agent is supposed to accomplish, you are not ready to build it.
That constraint eliminates most agent proposals circulating in organizations today. “Use AI to improve customer experience” is not a task. “Route inbound support tickets to the correct team based on the knowledge base” is a task. “Implement AI across the sales pipeline” is not a task. “Draft followup emails for deals that have been inactive for 7 days” is a task.
The deployments that work share three traits. One team built an AI that suggests solutions from their ITSM knowledge base and saw a 40% reduction in mean time to resolution. Another automated invoice scanning, going from 0.2 invoices per minute to 3 per minute, but it took 3 months to deploy because they built error handling at every step. A third team built separate Copilot Studio agents for mailbox monitoring, alert handling, and SLA checking. Each agent does one thing. The discipline of one task per agent is what keeps each one reliable.
An unexpected side effect appeared across several deployments. Preparing data and runbooks for agents forced teams to write better documentation. Processes that had lived as tribal knowledge finally got documented because the agent needed explicit instructions. The documentation improved the human workflow too.
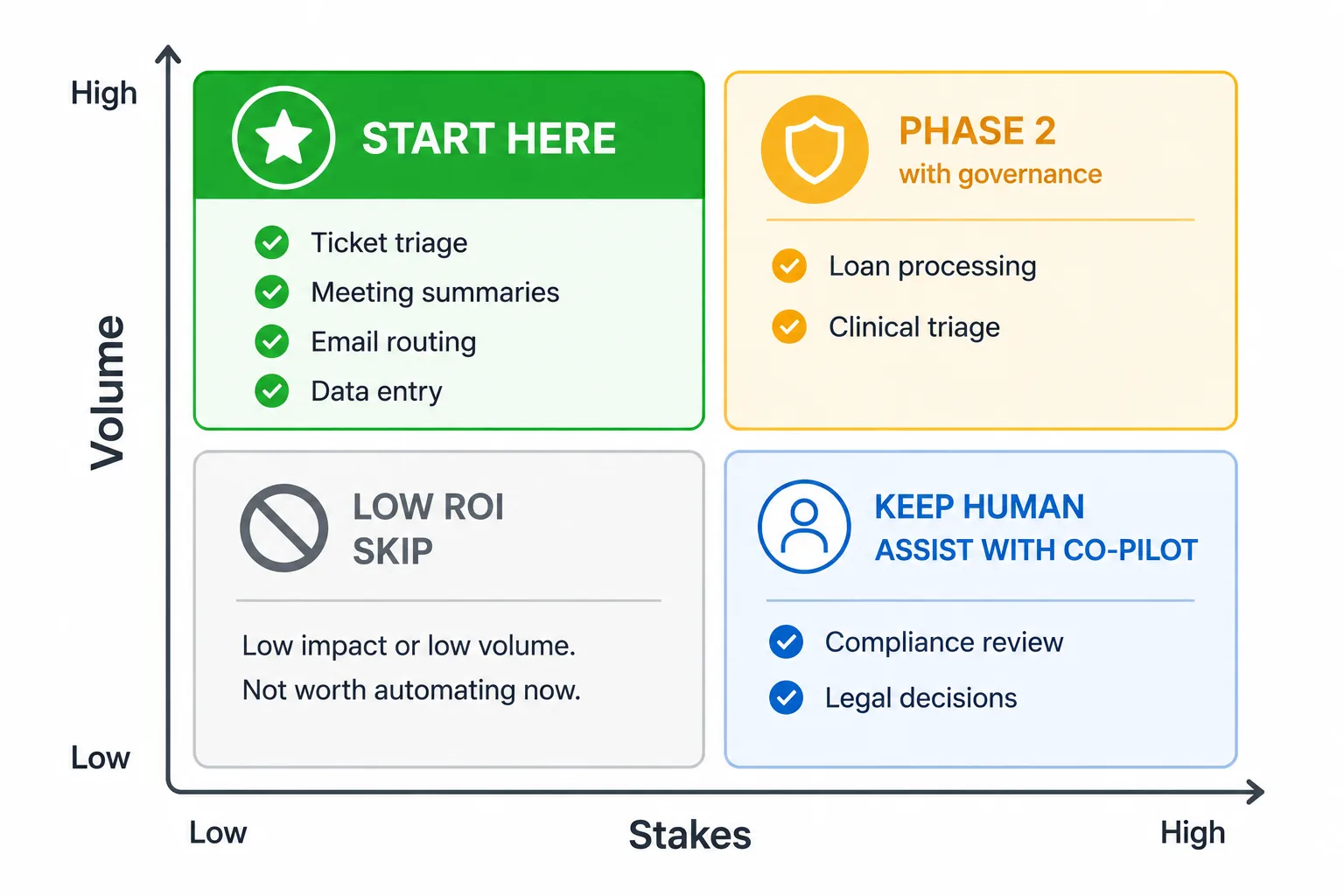
Fig 10. Workflow Selection Scorecard – Start in the high volume, low stakes quadrant.
Plan for attrition. 10 deployments per month does not mean 120 active agents in a year. Treat the first batch as experiments with defined success criteria and termination conditions.
The deployments that fail share a different trait. An IT auditor gave an AI a regulatory document and asked it to map topics to page numbers. The AI got every page wrong. CTRL+F found the answer in seconds. The task was wrong for the tool. Even at 80% accuracy, the cleanup effort on the remaining 20% often exceeds the time saved. The dashboard says 80% completion. The humans doing cleanup know the agent is a net negative on their time.
Fig 11. The 80% Accuracy Trap – When cleanup exceeds the time saved, the AI path is slower.
The same technology that fails at page lookup can process thousands of documents 100x faster than humans with a lower error rate, if the system is engineered correctly. The qualifier is “at scale.” This only makes economic sense when document volume is large enough that human processing takes weeks.
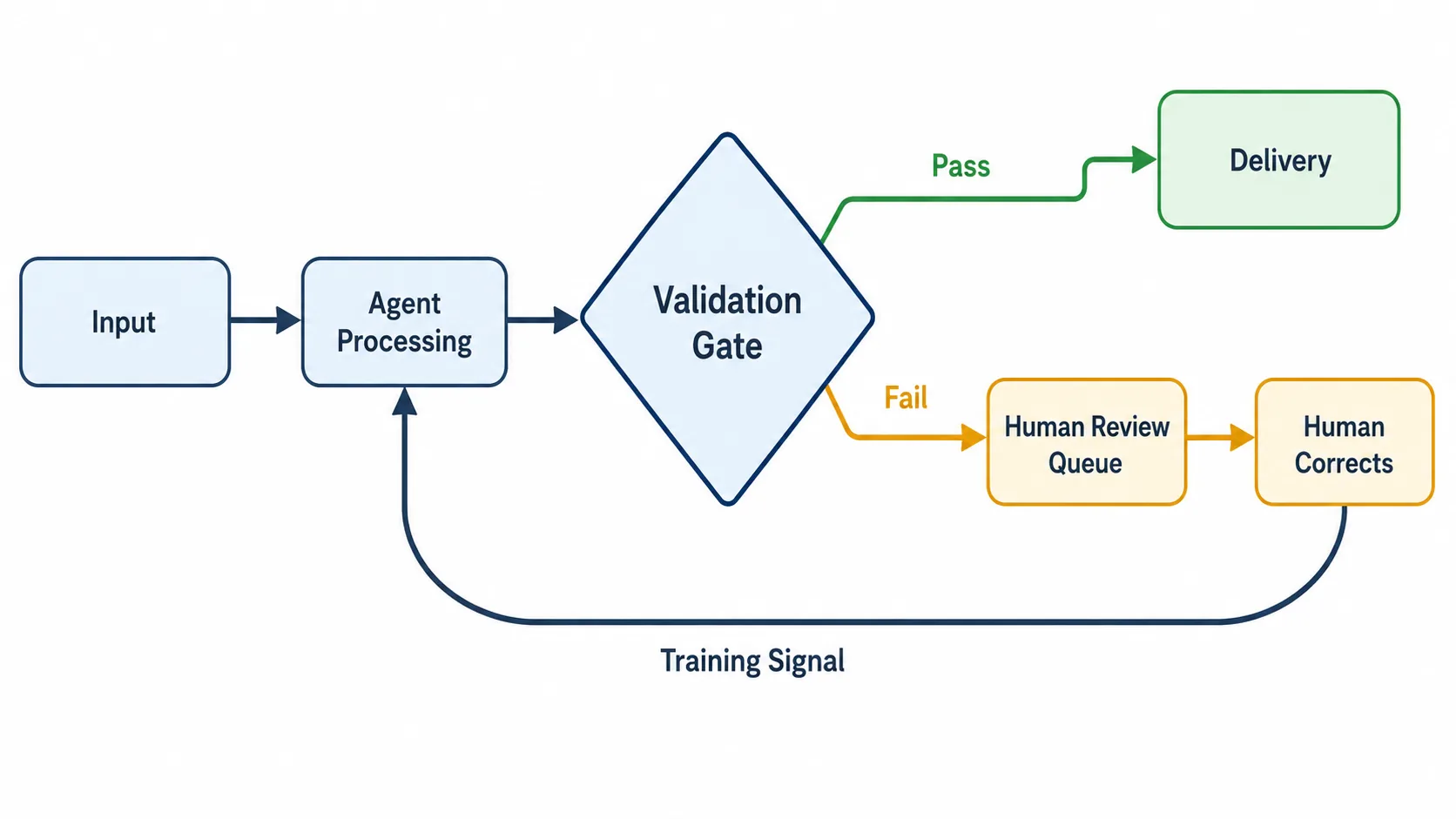
Fig 12. Build Around the Inaccuracies – Validation gates and human review turn model mistakes into a feedback loop.
The design principle that unifies the successes and explains the failures is straightforward. Build the product around the inaccuracies of the LLM. Assume the model will make mistakes. Design validation into the workflow. Route uncertain outputs to humans. Use the corrections as training signals.
Give a small team access to an LLM and an orchestration tool. Point each person at one real problem from their daily work. Build simple workflows. Sometimes a workflow with a single LLM call is the right solution. Show small wins early. A single agent that saves 4 hours per week on a visible process does more for buy in than a multi agent system that promises transformation and delivers complexity.
Governance Earns You the Right to Scale
Here is the math that kills multi agent ambitions prematurely.
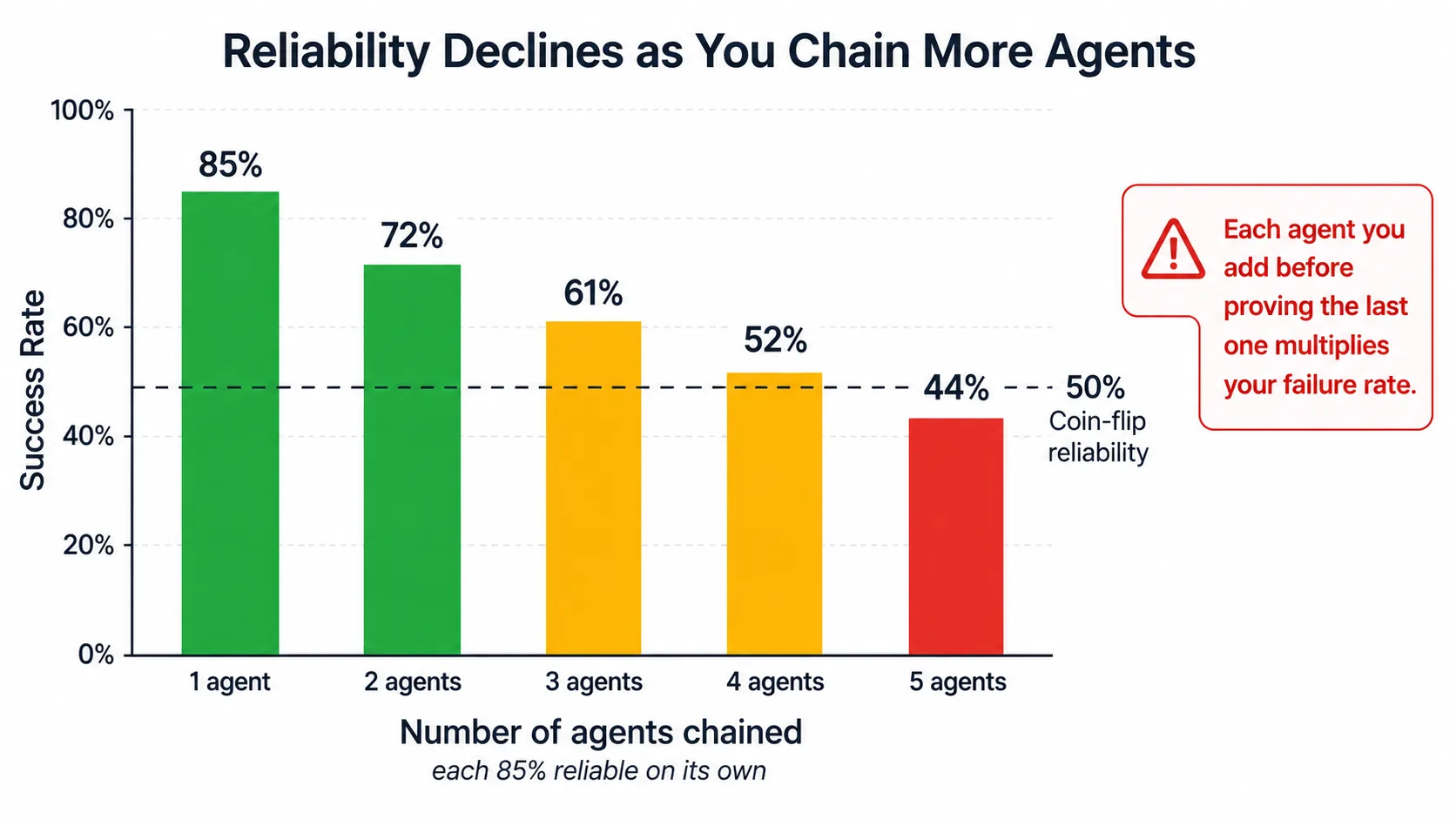
If one agent gets its task right 85% of the time, and a second agent in the same workflow also gets its task right 85% of the time, the combined process succeeds only 72% of the time. Add a third agent at 85% and the process drops to 61%. A fourth brings it to 52%. By the fifth agent in a chain, you are below coin flip reliability.
Fig 13. Compounding Error Rates – By the fifth chained agent, you are below coin flip reliability.
This arithmetic is why “prove one before you add the next” is risk management, not conservatism. And it is why governance must exist before scaling begins.
Every agent needs three things defined before it ships. Boundaries (what it can do, what it cannot do, what requires human approval). Escalation paths (how it hands work to a human with full context preserved). And audit trails (every input, reasoning step, tool call, and output logged).
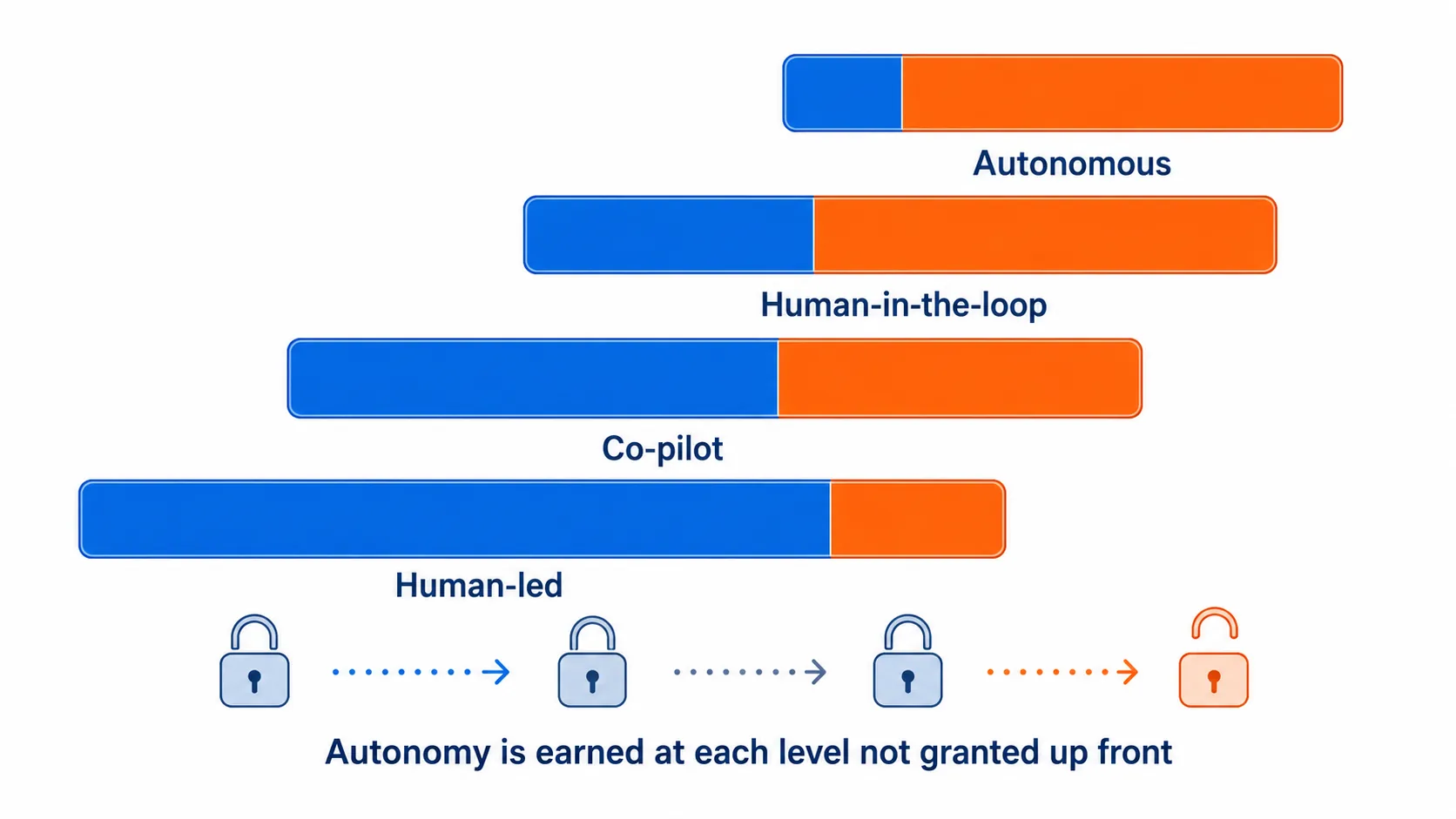
The earned autonomy ramp
The most effective deployments start by handling only the simplest, most repetitive decisions. The agent absorbs the routine calls and surfaces only the unusual cases to the human. Users feel supported. This builds trust. From there, the team collects data on which escalated cases the agent could have handled correctly. That data justifies expanding scope. Each expansion is earned through demonstrated reliability at the previous level.
Fig 14. The Earned Autonomy Ramp – Each expansion of scope is earned through demonstrated reliability.
Governance structure and kill criteria
A governance council composed of department heads, meeting monthly, creates the organizational structure for disciplined adoption. The agenda focuses on business challenges, not technology. Each proposed agent project documents the target workflow, expected business outcome, data sources, cost estimate, success criteria, and termination conditions through an AI business case canvas. The canvas prevents fantasy use cases from consuming engineering bandwidth.
Before deploying any agent, define the conditions under which it will be shut down. What metric triggers review. What metric triggers pause. What metric triggers permanent shutdown. Who has authority. How in flight work is handled. How to revert to the manual process. Without predefined kill criteria, failing agents persist because nobody wants to be the person who killed the AI initiative.
Decision Point
Trigger or Action
Review trigger
Human intervention rate above 30% for 2 consecutive weeks
Pause trigger
Cost per successful outcome exceeds the manual baseline
Shutdown trigger
Guardrail violations in 2 or more consecutive weeks
Authority
Named owner (e.g. Head of AI Ops) plus department head sign off
In flight handling
Complete active tasks, route new tasks to manual queue
Revert process
Reenable the manual workflow documented in the runbook
Log preservation
Export full trace logs to the archive before disabling
What Scaling Actually Looks Like
Once a single agent is producing measurable value, the next agent targets the next manual handoff in the same workflow or an adjacent one. A ticket triage agent might expand to include a resolution suggestion agent that reads the knowledge base. A meeting summarization agent might expand to include a followup task agent that writes action items into the project management system.
The production checklist for scaling includes six items.
Track financial performance against the baseline established in Start from What You Already Run. The baseline was the cost and time of the manual process. Every agent must demonstrate improvement against that baseline, accounting for token costs, human review costs, and error correction costs. If the agent path costs more than the manual path, the agent should be paused or retired.
How Clixlogix Approaches Agentic AI Projects
Clixlogix has delivered AI agent consulting and implementation since 2011 across the full spectrum of business maturity. For startups, that means scoping the first agent into an existing product without derailing the development roadmap. For mid market companies in healthcare, real estate, field services, hospitality, and ecommerce, it means layering agents onto the vertical specific workflows they already run, from patient engagement and property management to field dispatch and order fulfillment. For enterprise organizations, it means integrating agents into complex multi system environments where governance, compliance, and cross department coordination determine whether the deployment survives its first quarter. The approach follows the framework in this post. Inventory first. Single workflow proof. Measurement against an existing baseline. Governance before scaling. Incremental expansion earned through demonstrated results.
Goodhart’s Law and the Path Forward
There is an economic principle that explains why most agentic AI mandates produce motion without progress. Goodhart’s Law states that when a measure becomes a target, it ceases to be a good measure.
Charles Goodhart formulated this in 1975 while advising the Bank of England. The British government was trying to control inflation by targeting specific monetary measures. The moment those measures became official policy targets, financial institutions changed their behavior to hit the numbers, and the measures stopped reflecting the economic reality they were designed to capture. Goodhart observed that the act of targeting a metric destroys the information that metric was providing. The principle traveled far beyond central banking. Soviet nail factories judged on the number of nails produced millions of tiny ones too small to use. When the target switched to total weight, the same factories made a few giant nails nobody could use either. Whichever number was measured got hit. A useful supply of nails was never the result. Fifty years later, the same dynamic plays out in enterprise AI.
Fig 15. Goodhart’s Law in the Agentic AI Economy – When a measure becomes a target, it ceases to be a good measure.
The CEO who mandated 10 agentic AI deployments per month created exactly this condition. The number 10 became the target. Teams optimized for deployment count. Agents were built to exist, not to produce value. The metric told leadership that the company was “doing AI.” It told them nothing about whether AI was doing anything for the company. The resulting KPIs were not Key, and they did not Indicate Performance. They indicated compliance.
The alternative is to measure using the three tier framework described earlier in this post. Decision surface area reduced. Cost per successful outcome. Human intervention rate. Goal attainment. These metrics resist gaming because they require the agent to actually work. They cannot be inflated by deploying more agents. They can only be improved by deploying better ones.
The organizations closing the gap between pilot and production are not the ones moving fastest. They are the ones moving most deliberately. One agent. One workflow. One measurable outcome. Scaled only after the economics are proven and the governance is in place to sustain it.
Ready to Move from Mandate to Strategy?
If your team is stuck between a mandate from leadership and the operational reality of implementation, an outside assessment can bridge that gap. Internal teams who advocate for realistic scope are often perceived as resisting change. An external assessment carries structural credibility that internal recommendations do not.
Clixlogix’s AI Strategy consulting practice delivers a costed roadmap in a Discovery Sprint engagement. Use case prioritization, build vs buy analysis, governance framework, and a phased execution plan. Fixed scope. 2 to 6 weeks.
As CEO of Clixlogix, Pushker helps companies turn messy operations into scalable systems with mobile apps, Zoho, and AI agents. He writes about growth, automation, and the playbooks that actually work.