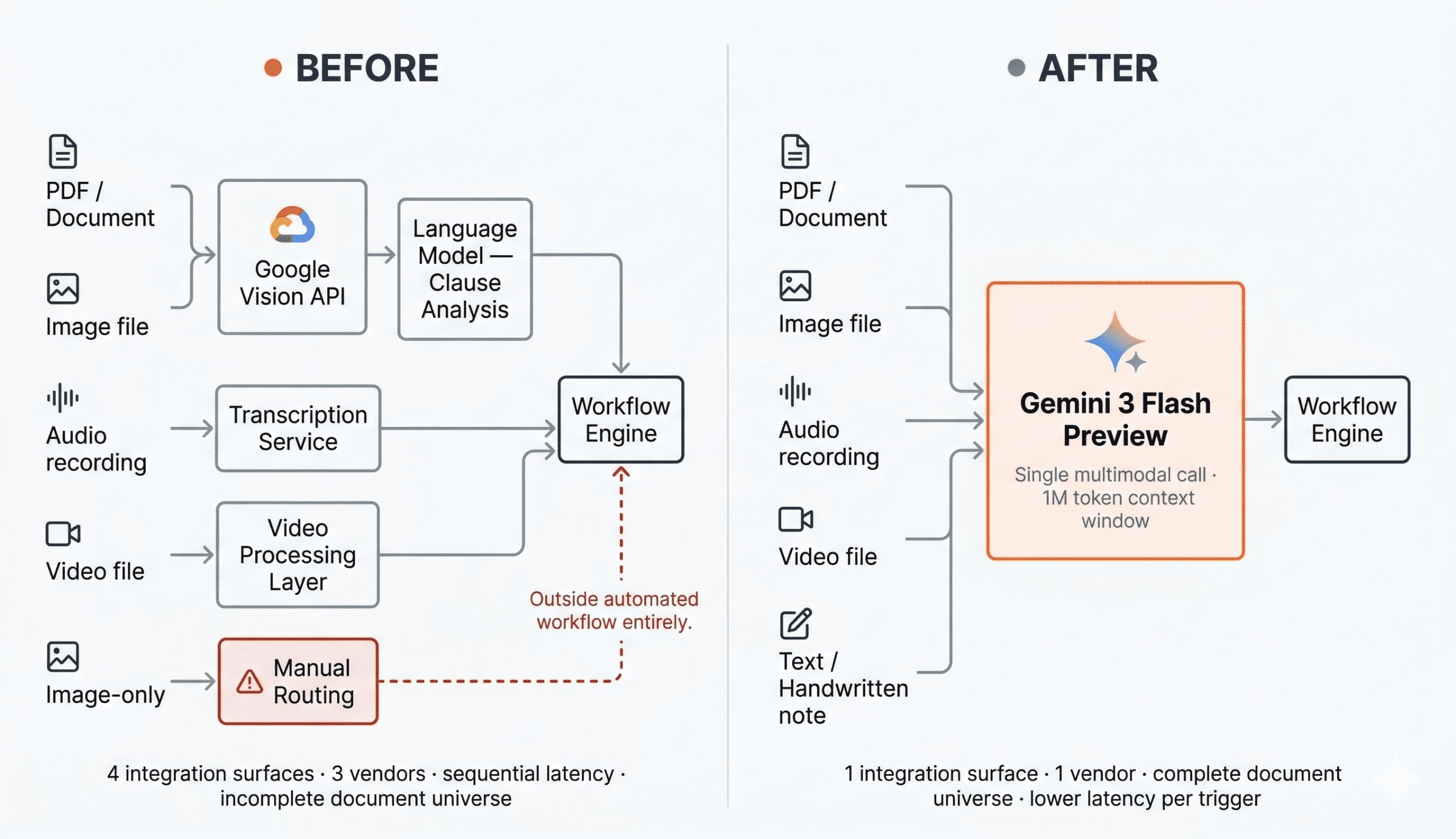
How an AI Legal Workflow CRM Outgrew Its Google Vision API OCR Pipeline
It started as an AI contract review tool. A Nordic legal tech startup had built a promising early product. Upload a PDF contract, get a structured clause by clause analysis back. The stack was straightforward, Google Vision API for text extraction, a language model for clause interpretation. Clean scope. Manageable pipeline. The kind of thing you can ship in a few months with a well understood stack.
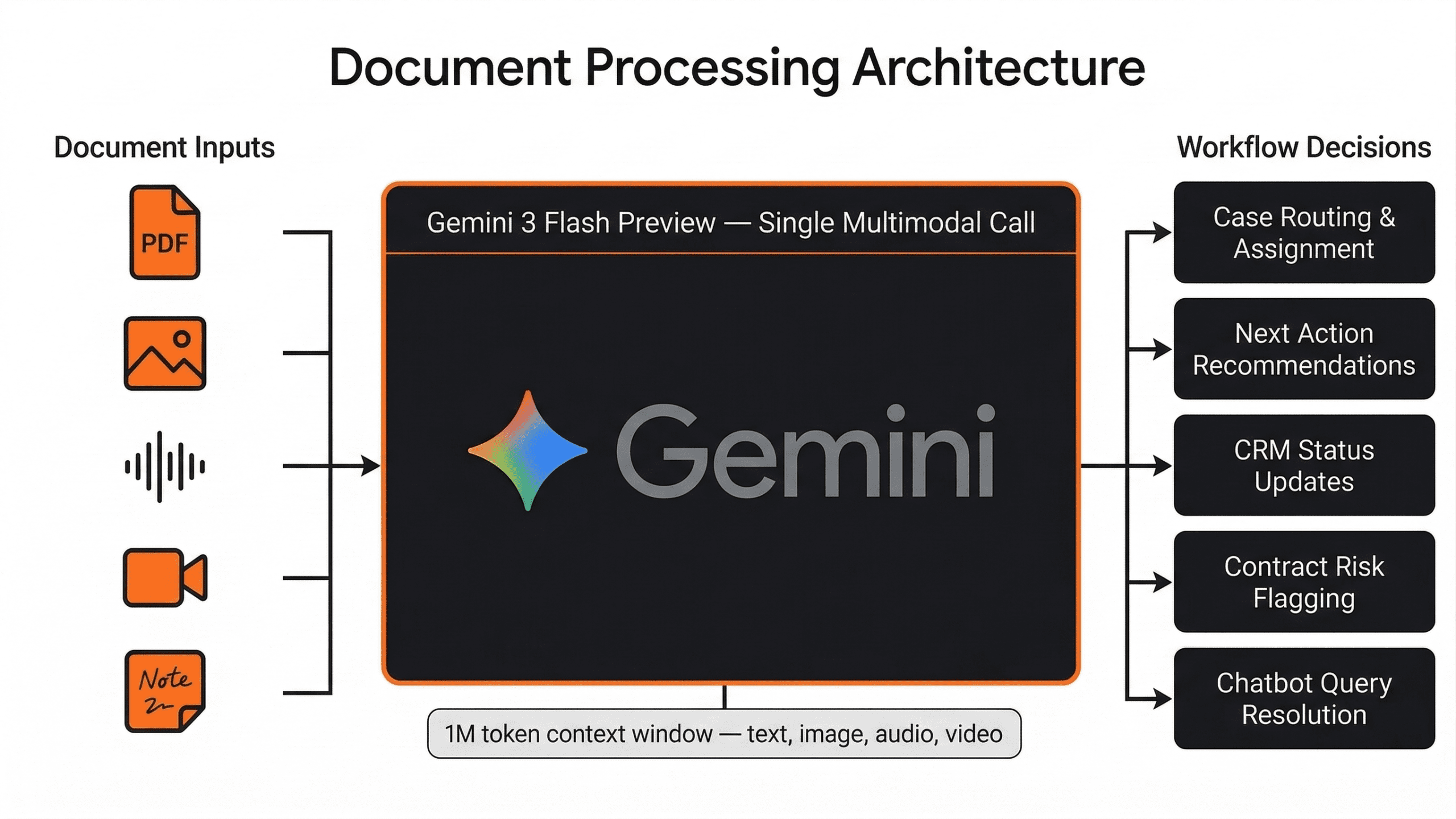
From the beginning, parsed document outputs fed directly into a custom built legal workflow engine, cases were routed and assigned based on contract type and risk signals extracted from the document, next actions were recommended to attorneys based on clause analysis, CRM status updates were triggered automatically as documents moved through review stages, and contract risk flags were surfaced for attorney attention without manual triage. A dual mode AI chatbot sat on top of the same document understanding layer, client facing for end users interacting with the platform, and internal for attorneys querying their own case files directly. The model was not displaying text. It was running a decision loop.
By the time ClixLogix joined the engagement, the scope had shifted fast. Within three weeks of launch, the client’s users were asking for more. The users were asking for scanned case files, handwritten notes, court photographs, audio recordings of depositions, video from proceedings, well beyond the original PDF scope.”. The platform had pivoted, almost overnight, from a contract review tool into a full legal AI workflow automation system handling the entire case lifecycle across five media formats and two languages.
The original architecture had not been designed for this. And the cracks were already showing.
The platform was parsing documents to make decisions, routing cases, flagging risk, triggering workflow steps, and answering attorney queries in real time.
The Legal Workflow CRM Decision Engine
Understanding why document parsing accuracy mattered at this level of consequence requires understanding what the parsed output was used for. The custom workflow engine consumed model output across five decision types:
Case routing and assignment – Contract type, jurisdiction, and party identification extracted from documents determined which attorney or team received the case.
Next action recommendations – Clause analysis and document completeness signals generated recommended next steps surfaced to attorneys in the workflow interface.
Automated CRM status updates – Document review milestones, contract received, clauses flagged, risk assessed, triggered status transitions in the case management system automatically.
Contract risk flagging – Specific clause patterns, missing provisions, and anomalous terms identified during parsing surfaced as risk alerts for attorney review.
Chatbot query resolution – Client facing users queried case status and document content through a conversational interface. Attorneys used the same layer to interrogate case files directly. Both modes depended on accurate document understanding to return grounded, reliable responses.
A character substitution error in a party name produced a misrouted case. A layout parsing failure that split a clause incorrectly generated a wrong next action recommendation. The downstream cost of OCR inaccuracy in this architecture was operational
Fig 1. Legal workflow CRM architecture, document inputs processed by Gemini 3 Flash Preview driving five automated workflow decisions
The Google Vision Document Processing Pipeline
The existing stack was logical for its original purpose. Google Cloud Vision API handled text extraction from PDFs and images, passing the result downstream to a language model for clause interpretation and structured output. Two discrete steps. Step 1 – extract, then Step 2 – reason. Each step calls a separate API. Each step adds latency. Each step represents a seam where information could be lost.
For clean, digitally generated PDFs in English, it worked adequately. But the client’s document universe was not clean, and it was not English.
Google Vision API OCR Failures on Nordic Legal Documents and Their Workflow Consequences
Nordic legal documents, Swedish, Norwegian, Danish, contain characters that Google Vision’s OCR handled inconsistently under real workload conditions. Diacritics like å, ä, ö, Æ, Ø were regularly substituted with basic Latin equivalents. In a document display tool, these are rendering errors. In a legal workflow CRM where party names drive case routing, they were misassignment errors. A contract involving a Danish counterparty whose name contained Ø was being routed as an unrecognised entity. The workflow engine was making correct decisions based on incorrect inputs.
The structural problems compounded this. Legal documents carry meaning in their visual hierarchy, numbered clauses, indented sub provisions, tables of defined terms, cross reference annotations in margins. Google Vision’s OCR extracted characters without preserving spatial structure. A table of defined terms came back as a flat stream of text. Sub clauses lost their parent context and appeared as independent provisions. When the workflow engine consumed this output to generate next action recommendations, it was reasoning over a document that no longer resembled the original. Clause completeness checks failed on documents that were complete. Risk flags triggered on provisions that were standard because their context had been stripped.
Then there were the image only case files, scanned photographs of physical documents, photographs of whiteboards from proceedings, images submitted as evidence. For these, the OCR pipeline was effectively blind. The client’s team had been routing them manually, which meant those cases sat outside the automated workflow entirely. The chatbot could not answer queries about them. CRM status updates were not triggered. The decision engine had a gap in its document universe that grew as the platform scaled.
Fig 2. Google Vision API OCR diacritic failure on Nordic legal documents, corrupted party names produced misrouted cases in the workflow engine
The structural problem with two step pipelines
Step 1 extracts characters. Step 2 reasons over them. Between those two steps, the layout is gone. Hierarchy is gone. Visual context is gone. The language model never sees what the document actually looks like. It sees a character stream and is asked to infer structure from it. For intelligent document processing, that inference is frequently wrong in consequential ways.
The audio and video requirements made the multipipeline problem explicit. There was no clean way to route deposition audio or proceeding video through the existing stack. Each new media type required a separate integration for a transcription service for audio, a video processing layer for footage, a vision API for images, a PDF extractor for documents, and then an aggregation step before anything could be reasoned over. The architecture was becoming a collection of integrations rather than a system.
GDPR and Data Residency Requirements for AI Document Processing
Any discussion of AI document processing in a legal context runs into a constraint that does not apply in the same way in other markets: data residency. Nordic regulators implement GDPR through national legislation, the Danish Data Protection Act, the Norwegian Personal Data Act, and their Swedish equivalent and have actively enforced high risk processing rules for the kind of large scale document analysis that a legal AI platform performs. Case files, contracts, and deposition records routinely contain personal data, special category information, and material subject to legal professional privilege. Processing that data through AI services with US based infrastructure creates obligations that Nordic organizations have become increasingly reluctant to accept.
The regional pattern is visible and accelerating. Nordic organizations have moved away from US centric cloud tools toward EEA based or locally hosted alternatives specifically to guarantee that client and case data used in AI workloads stays within the European Economic Area. Nordic data protection authorities have taken enforcement positions that certain US hosted analytics tools violated GDPR due to inadequate safeguards against foreign surveillance. For a legal tech startup whose clients are law firms and legal departments, this is not a peripheral compliance concern. It is a sales prerequisite.
This context shaped several architectural decisions that might otherwise have appeared to be purely technical choices. The system was designed so that client document data did not flow into shared model training pipelines. Processing agreements covered Vertex AI’s enterprise data handling commitments, which include contractual guarantees that customer data is not used to train shared foundation models. Tenant isolation, encrypted storage, and auditable access logs were first class requirements from the start. The architecture that simplified the media processing pipeline also reduced the number of vendors handling sensitive document data from four to one, which simplified the data processing agreement surface considerably.
Nordic regulatory context in practice
GDPR risk classification – Legal case files and contracts are high risk personal data.
DPIA obligation – Large scale AI document analysis typically requires a Data Protection Impact Assessment.
EEA residency preference – Nordic organizations increasingly require AI workloads to stay within the EEA.
Training data restriction – Client documents must not be used to train shared foundation models.
Audit requirement – Access logs and processing records must support regulatory accountability.
Architecture implication – Fewer vendors processing sensitive data means a smaller, cleaner DPA surface.
The broader legal tech market reflects the same priorities. AI contract review and document analytics have become mainstream across the region, but adoption is conditioned on vendors demonstrating privacy compliance and regulatory alignment, not just technical capability. Architecture that cannot answer the GDPR question does not get deployed in this market, regardless of how capable the underlying model is.
Why Gemini Multimodal Document Processing Replaced the Two Step OCR Pipeline
The decision to evaluate Gemini was straightforward on paper: it was the only model in the accessible cost tier that handled text, images, PDFs, audio, and video natively within a single API call and a one-million-token context window. The question was whether Gemini’s multimodal capability was good enough at each modality to replace dedicated tools that had been tuned for specific tasks.
Gemini 2.0 Flash Lite was selected as the baseline for the initial evaluation. The rationale was deliberate: at approximately ₘ0.07 per million input tokens, it was the most cost efficient entry point in the Gemini 2.0 family. For a startup processing variable document volumes with unpredictable monthly throughput, the cost structure mattered as much as capability. Flash Lite allowed the team to validate the architectural approach, single model, single call, unified context, before committing to higher per token costs for production scale.
The architectural simplification was immediate and significant. The new pipeline passed the raw asset, PDF, image, audio, video, directly to Gemini, bypassing the dedicated extraction layer entirely. The model handled modality specific processing internally. One API. One response. One integration surface to maintain.
The old pipeline asked: what text does this document contain? The new pipeline asked: what does this document mean? The difference in question determined the difference in output quality.
What the team observed in early testing confirmed the architectural hypothesis. Gemini saw documents the way a lawyer would: as structured objects with visual hierarchy, not as character streams. It recognized that an indented clause was subordinate to the clause above it. It understood that a table of defined terms had semantic relationships between columns. It could identify a handwritten annotation in the margin and relate it to the clause it annotated. None of this required post processing heuristics. It was simply what the model returned.
Gemini 2.0 Flash Lite OCR Quality Issues That Drove the Model Upgrade
Flash Lite 2.0 was not without issues. Under production conditions, the team observed the same category of problems that the broader developer community was encountering, inconsistent handling of structured tabular inputs, occasional character recognition regressions on dense documents, and instruction following failures on edge cases where the prompt specified precise output formatting for complex clause structures.
In a legal workflow context where output feeds into attorney review and client facing documents, inconsistency at the extraction layer is not acceptable at scale. The team was spending engineering time on prompt hardening and output validation that should not have been necessary.
The model was also, in a practical sense, already on borrowed time. Google had been signaling movement in its model family throughout 2025, and the developer community had grown accustomed to short notice deprecation cycles. A model that was “cost efficient” today could be sunset with weeks of notice, requiring emergency migration work that disrupted production systems and consumed engineering capacity that should have been directed at product development.
What the developer community was saying
Across Google’s own forums, developers using Flash Lite 2.0 for OCR adjacent tasks reported:
Character recognition regressions on dense or structured documents
Instruction following failures on tabular outputs with complex conditions
Diacritic substitution errors (‘e’ appearing as ‘ë’ or ‘è’) on non English text
These were precisely the failure modes the we were observing on legal documents.
Migrating to Gemini 3 Flash Preview
The deprecation announcement for Gemini 2.0 Flash Lite arrived by email. The quality issues the team had been managing provided context for what otherwise might have felt like a purely administrative notice. The model was being retired. Migration was required. The deadline was defined.
The Google Cloud deprecation notice received by the client, requiring migration to Gemini 3.1 Pro Preview, 3 Flash Preview, or 2.5 Pro GA.
For ClixLogix and the client, the deprecation email landed differently. The quality issues with Gemini Flash Lite had already made the case for moving to a more capable model in the family. The deprecation notice confirmed the timeline. The combination of reasons, quality ceiling hit, model lifecycle risk confirmed, made the migration decision straightforward rather than disruptive.
The deprecation email confirmed what the quality evidence had already established, migration was the right call.
How to Migrate from Google Vision API to Gemini
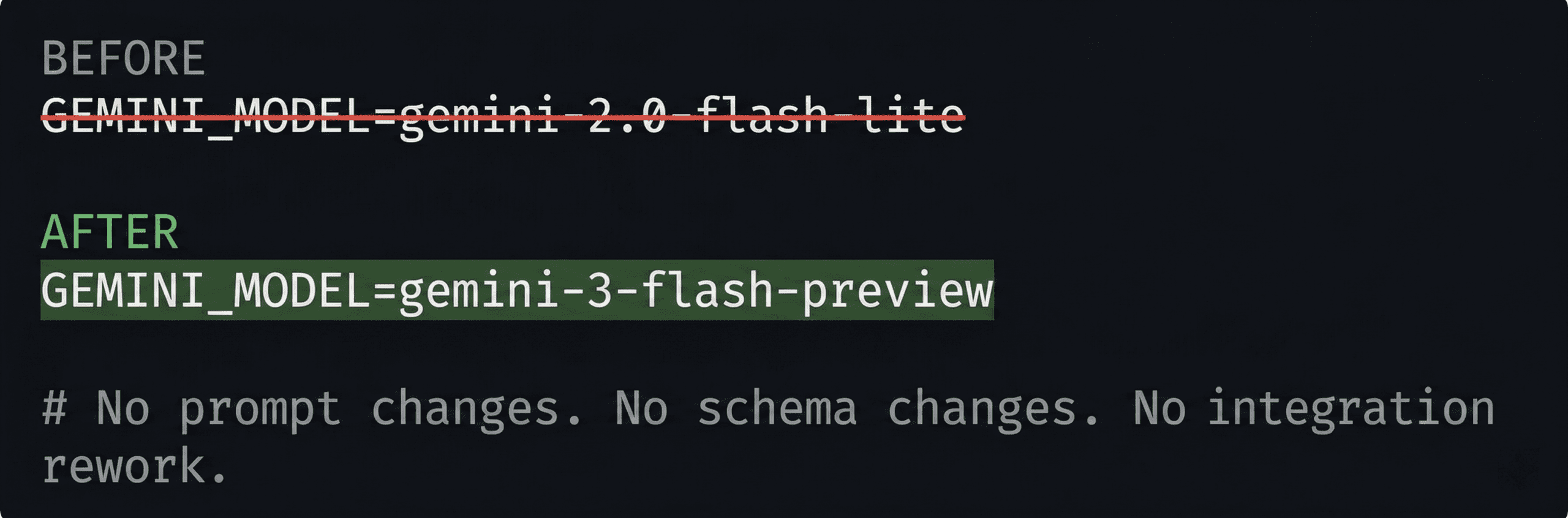
The migration from Gemini 2.0 Flash Lite to Gemini 3 Flash Preview took less than a day. The model identifier was stored as an environment variable. Updating it to point to the new model string was the entirety of the deployment change. No prompt rewriting. No output schema changes. No integration rework.
This outcome was a direct consequence of how the system had been architected from the start. The model was an interchangeable component behind an abstraction layer. The interface between the application and the model was clean. When the model changed, the interface did not.
The lesson applies to any AI component in a production system – the implementation detail of which model you are calling should never be embedded in your application logic. If swapping your model requires touching your prompt templates, your output parsers, or your downstream data structures, the coupling is too tight. The system should be designed so that model layer changes are configuration changes, not engineering projects.
Fig 3. The complete migration from Google Vision API pipeline to Gemini Flash Lite to Gemini 3 Preview, one .env variable, no integration rework
What Changed
Result
Model identifier
One .env variable updated
Prompt templates
No changes required
Output schema
No changes required
Integration layer
No changes required
Downstream systems
No changes required
Deployment time
Under one day
Gemini Document Processing Results For Accuracy and Latency
The improvements from moving to Gemini 3 Flash Preview were observable across the document extraction layer and, critically, across the workflow decisions that depended on it. On structured document extraction, the tabular output consistency issues that had required prompt hardening workarounds largely resolved. The model followed complex formatting instructions reliably. On Nordic language documents, the diacritic handling improved measurably, the character substitution errors that had been producing misrouted cases and incorrect party identification were no longer present at the same rate.
Case routing accuracy improved as a direct consequence. Party names, contract types, and jurisdictional signals extracted from documents were now consistent enough that the workflow engine’s routing logic could rely on them without manual review intervention. Contract risk flagging became more reliable as clause boundary detection improved, the workflow engine was no longer generating false positives from clauses that had been incorrectly split across what the model treated as paragraph boundaries. Next action recommendations became grounded in the actual document structure rather than a flattened character stream.
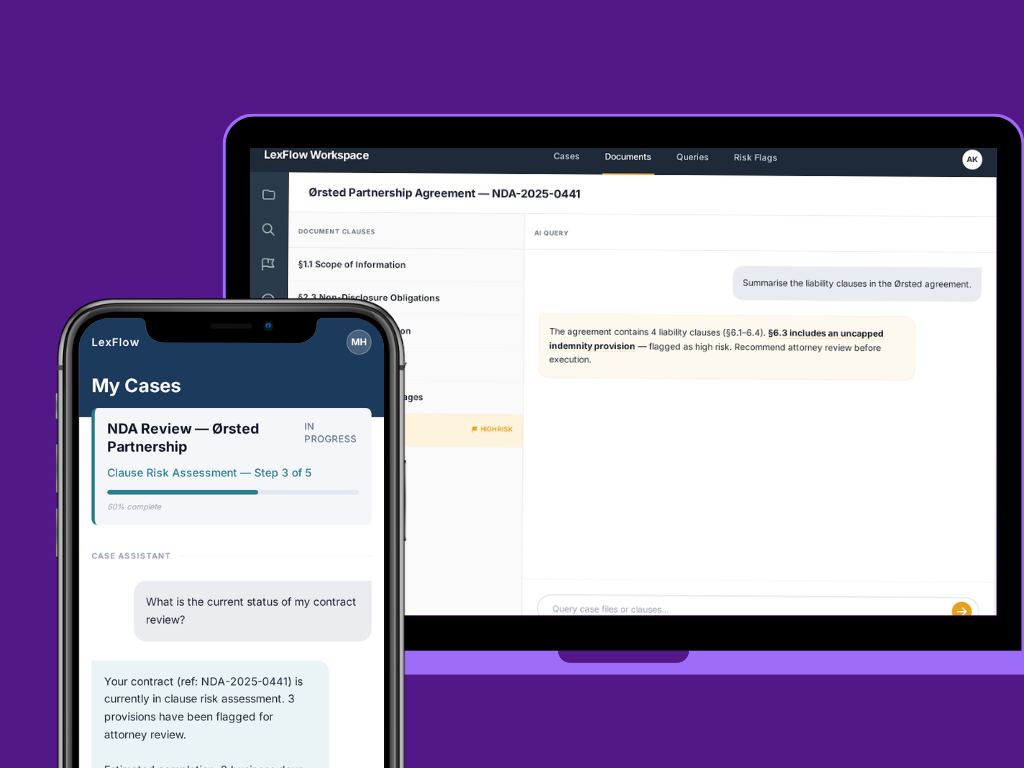
Latency dropped, and this mattered directly to the workflow UX. The single call architecture eliminated the round trip overhead of the 2 step extract then reason pipeline. For a legal workflow CRM where an attorney’s next action recommendation and CRM status update both depended on the model’s document response, every second of pipeline latency was a second the interface sat waiting before the workflow could advance. The chatbot, used by both end users querying case status and attorneys interrogating case files, became noticeably more responsive. Queries that had required two sequential API completions now resolved in one.
Fig 4. Dual-mode AI chatbot powered by Gemini document processing, client portal (left) and attorney case file query interface (right)
Latency dropped, and this mattered directly to the workflow UX. The single call architecture eliminated the round trip overhead of the 2 step extract then reason pipeline. For a legal workflow CRM where an attorney’s next action recommendation and CRM status update both depended on the model’s document response, every second of pipeline latency was a second the interface sat waiting before the workflow could advance. The chatbot, used by both end users querying case status and attorneys interrogating case files, became noticeably more responsive. Queries that had required two sequential API completions now resolved in one.
Fig 5. Google Vision API pipeline vs Gemini multimodal document processing, vendor surface, latency and document universe compared
The media handling capability that had motivated the architectural change performed as expected. Audio recordings of depositions, processed through the same model as PDF contracts and photographic evidence, returned structured output the workflow engine could consume uniformly. The image only case files that had been manually routed around the system were now processed automatically, they entered the workflow, triggered CRM status updates, and became queryable through the chatbot. The decision engine’s document universe was complete for the first time.
The Architectural Lesson on Gemini Multimodal Document Processing
Intelligent document processing pipelines that split extraction and reasoning into separate steps are making a structural trade off since they are optimising for the tools that existed before models could handle multiple modalities natively. That trade off made sense in 2022. It makes less sense now. The cost of maintaining multiple extraction layers, managing multiple vendor relationships, and absorbing the latency of sequential API calls is a tax on the architecture. It is a tax that compounds as document complexity and media variety increase.
The more useful question when designing any AI document processing system today is whether the system needs separate extraction and reasoning steps at all. For legal documents, for clinical notes, for financial contracts, for any domain where visual structure carries semantic meaning, the answer is increasingly no. A model that understands the document as a whole, layout, hierarchy, language, annotations, will outperform a pipeline that strips that context away before reasoning begins.
The caveat is for high volume processing of simple, digitally generated, English language documents where character perfect extraction is the only requirement, a dedicated OCR tool may still be faster and cheaper. The decision is not universal. But the threshold for when a multimodal model is the correct architecture has moved significantly in the past eighteen months, and many systems designed before that shift are now carrying unnecessary complexity.
It is also worth being specific about where multimodal models continue to struggle. Independent benchmarking on visually complex inputs, television news frames with overlapping text, multiple fonts, and moving backgrounds, has found that LMMs including Gemini can perform surprisingly poorly compared to traditional OCR on character perfect extraction tasks, and can occasionally hallucinate by silently correcting text to what they expect rather than what is written. For legal documents, where a defined term must match its definition exactly across every clause in which it appears, this failure mode is not theoretical. It is the reason output validation remains a required layer regardless of which model handles extraction. The architectural shift from two-step pipelines to single multimodal document processing calls reduces complexity. It does not eliminate the need for downstream verification on high stakes outputs.
Decision Framework for Google Vision API Pipeline vs Gemini Multimodal
The table below reflects observed behaviour from this engagement and published benchmarks. It is intended as a practical reference for teams evaluating whether to replace a Google Vision API OCR pipeline with a Gemini multimodal document processing architecture.
Dimension
Google Vision API Pipeline
Gemini Multimodal (Single Call)
Modalities supported
Text and images (PDFs). Audio and video require separate services.
Two sequential API calls minimum. Each hop adds round trip latency.
Single API call. No interservice round trips. Lower end to end latency.
Nordic language / diacritic handling
Inconsistent. å, ä, ö, Æ, Ø substituted with Latin equivalents under load. Persistent issue in developer forums.
Improved handling. Character substitution errors reduced measurably on Nordic legal documents in production.
Layout and structure preservation
Extracts characters. Spatial hierarchy (clauses, sub provisions, tables) lost before the language model sees the document.
Preserves document structure. Understands indentation, table relationships, and cross references as part of reasoning.
Cost per call
Vision API: ~$1.50 per 1K pages. Plus downstream LLM cost as a separate charge.
Gemini 3 Flash Preview: single unified call. No additive per modality charges for multiformat documents.
Vendor surface / integration complexity
Multiple vendors: Vision API, transcription service, video processor, LLM. Four integration surfaces to maintain.
Single vendor, single API, single data processing agreement. Substantially simpler integration surface.
GDPR / data residency posture
Multiple vendors require multiple DPAs. Each service must individually meet EEA residency and data handling requirements.
Single Vertex AI DPA. Contractual guarantee that customer data is not used to train shared models. Cleaner GDPR surface.
Migration effort (from Vision API pipeline)
N/A — this is the legacy architecture.
Model identifier change in .env. No prompt rewriting, schema changes, or integration rework required.
Sources: Google Cloud Vision API pricing documentation; Gemini API technical documentation; developer forum reports (Google AI Developer Forum, Sept 2025); ClixLogix production deployment observations, 2025.
Build your abstraction layer correctly and model upgrades become configuration changes. Build it incorrectly and every deprecation email becomes an engineering project.
Managing Google Cloud Model Deprecation Risk in AI Document Processing Systems
One observation from this engagement that has broader applicability is that the risk of building on a specific model is real, but it is manageable. Google’s deprecation practices are imperfect. Short notice shutdowns have caused genuine disruption for teams that had tight coupling between their application logic and specific model endpoints. That risk is an argument for how the integration should be designed vs model selection.
The teams that absorbed deprecations cleanly, including this engagement had built systems where the model identifier was a configuration value, not an assumption embedded in the codebase. The teams that scrambled had built systems where changing the model required changing the product. The difference in outcome had nothing to do with which model was chosen. It had everything to do with how the integration was designed.
A separate issue worth naming directly, Gemini API latency under production load is a genuine and well documented complaint in the developer community. The gap between response times in AI Studio and response times through the production API has been reported consistently, and the causes, regional endpoint routing, cold start behaviour on certain model configurations, context window size relative to prompt structure are engineering problems, not model problems.
The mitigations however are available, regional endpoint selection, context caching for high repetition document templates, and request batching for non realtime workflows. None of these require switching models. They require treating latency as a first class architectural concern from the start, not a problem addressed after deployment.
Model families will continue to evolve. Deprecation cycles will continue to compress as providers push newer generations faster. The appropriate response is to architect for replaceability from day one.
Yes, but the replacement is architectural, not just a model swap. Google Vision API is a dedicated OCR service, it extracts text characters from images and PDFs and returns a string. Gemini is a multimodal model that processes the raw document directly and returns structured understanding. The difference is that Gemini does not need a separate reasoning step after extraction. For workloads where extracted text feeds into a language model anyway, replacing both steps with a single Gemini call simplifies the pipeline, reduces vendors, and eliminates the information loss that happens between extraction and reasoning.
Google Vision API performs well on clean, digitally generated English documents. On documents containing Nordic characters (å, ø, æ, ä, ö), Cyrillic, Arabic, or other non Latin scripts, character substitution errors are common, particularly on scanned or photographed documents with moderate noise. For legal, medical, or financial workflows where party names, clause references, and numeric values must be exact, these substitution errors propagate downstream and cause workflow failures that are difficult to detect and expensive to correct manually.
Google Vision API charges approximately $1.50 per 1,000 pages for document text detection. Gemini 2.0 Flash Lite was priced at roughly $0.07 per 1 million input tokens, with a PDF page consuming approximately 250 to 300 tokens of context. For a standard legal contract of 10 to 15 pages, a single Gemini call costs a fraction of a cent. The more relevant cost comparison is total pipeline cost, Google Vision API plus a downstream language model call plus any separate audio or video processing services versus a single Gemini call covering all media types. The single call architecture is cheaper at moderate volumes and meaningfully cheaper at scale.
Gemini’s multimodal input supports PDFs, images (JPEG, PNG, WebP, HEIC), audio files (MP3, WAV, FLAC, AAC), video files (MP4, MOV, AVI, MKV), and plain text, all within a single API call and a shared 1 million token context window. This means a document set that previously required four separate processing pipelines, OCR for PDFs and images, transcription for audio, video processing for footage, and a text handler for plain files, can be routed through a single integration surface with unified output.
If your pipeline is built with clean abstraction then the model identifier can be stored as a configuration value, prompts and output schemas decoupled from the extraction layer, migration is a configuration change. Update the model string, verify output schema compatibility, and run regression tests on a representative document sample. If your pipeline has tight coupling between the extraction step and the reasoning step, migration requires separating those concerns first. The migration itself is not the hard part. The abstraction layer is.
Yes. Gemini processes image inputs directly, which includes scanned documents, photographed contracts, and handwritten notes. Gemini processes the visual layout, handwriting style, and document structure as part of the same inference, the image goes in, structured understanding comes out. Performance on low quality scans or dense cursive handwriting varies, and output validation is still recommended for high consequence workflows, but the capability gap that made image only documents invisible to OCR based systems does not apply.
OCR, optical character recognition, converts document images into machine readable text. It is a character extraction process with no understanding of what the text means, how it is structured, or what decisions it should inform. Intelligent document processing uses the extracted content as input to reasoning systems that classify, structure, and act on document content. The distinction matters because OCR quality directly constrains IDP quality, errors introduced during extraction propagate through every downstream decision. Multimodal models like Gemini collapse the extraction and reasoning steps into a single inference, which removes that propagation risk for most document types.
Gemini accessed through Google Cloud’s Vertex AI platform includes enterprise data processing agreements that provide contractual guarantees against customer data being used to train shared foundation models. For EEA based workloads, Vertex AI supports regional endpoint selection that keeps data within European infrastructure. This does not eliminate GDPR obligations, organizations processing special category data such as legal case files, medical records, or financial documents still need to conduct data protection impact assessments and maintain audit logs, but it addresses the data residency and training data concerns that have made US hosted AI services problematic for European regulated industries.
Google Cloud’s model deprecation cycle for Gemini has run on timelines of six to twelve months between announcement and end of life, with migration paths recommended in the deprecation notice. The operational risk is manageable if the model identifier is stored as a configuration value rather than embedded in application code. Systems where prompts, output schemas, or downstream integrations are tightly coupled to a specific model version face significant reengineering costs at each deprecation cycle. The architectural principle is that the model should be an interchangeable component, the system’s behaviour is defined by its prompts and schemas, not by which model executes them.
The most common cause is layout parsing failure during document extraction. When an OCR or extraction layer incorrectly identifies clause boundaries, splitting a single clause across what it treats as separate paragraphs, or merging adjacent clauses, the reasoning model downstream receives malformed input. Risk flagging logic that looks for specific clause patterns will generate false positives from fragments that resemble risk indicators but are artefacts of parsing rather than genuine contractual provisions. Improving extraction quality, particularly clause boundary detection, reduces false positive rates more reliably than tuning the risk flagging logic itself.
Yes, and this is one of the higher value automation patterns in legal operations. The typical implementation extracts document review milestones, contract received, clauses identified, risk assessment complete, attorney review triggered, and maps those milestones to CRM status transitions via webhook or API. The accuracy requirement is higher than for display only use cases because a missed or incorrect status update affects case assignment, billing triggers, and deadline tracking downstream. Production implementations generally include a confidence threshold below which status updates are queued for manual review rather than applied automatically.
Gemini Flash models are optimised for speed and cost efficiency, lower latency per call, lower price per token, suitable for high volume document processing where throughput matters. Gemini Pro models offer higher reasoning quality and are better suited to complex multi document analysis, nuanced clause interpretation, or tasks requiring extended chain of thought. For a legal workflow CRM processing routine contract intake, extraction, classification, risk flagging, routing, Flash is the appropriate choice. Pro becomes relevant for adversarial contract review, cross document precedent analysis, or other tasks where reasoning depth justifies the cost and latency premium.
Written By
Chief Executive Officer
As CEO of Clixlogix, Pushker helps companies turn messy operations into scalable systems with mobile apps, Zoho, and AI agents. He writes about growth, automation, and the playbooks that actually work.
Store owners in Shopify have noticed something unsettling. Traffic patterns are changing. Pages that used to rank well are getting fewer clicks, even though rankings...