The Shorts Video Factory
A global eCommerce brand wanted to compress the time between “new product” and “believable ad.” We wondered if a workflow engine could handle that job, if software could take a product image, imagine a believable context, and return a usable short video that promotes a product / service using POV or Faceless format. We built a AI video generation workflow using n8n and Google’s Nano Banana (Veo). Principles and guardrails behind this n8n workflow also revolve around the Field Guide to building n8n workflows that we published earlier last week.
The pipeline turns inputs into motion , generating personas, scripts, and frames, then rendering handheld clips automatically. The system prepares a portrait frame, and asks the model to render 4 to 8 second clips good for TikTok, Instagram Reels and Youtube Shorts.
Video Generation Workflow System
The pipeline looks simple on a whiteboard – ingest, decide, effect, observe. That four-stage rhythm held up well when the workload grew.
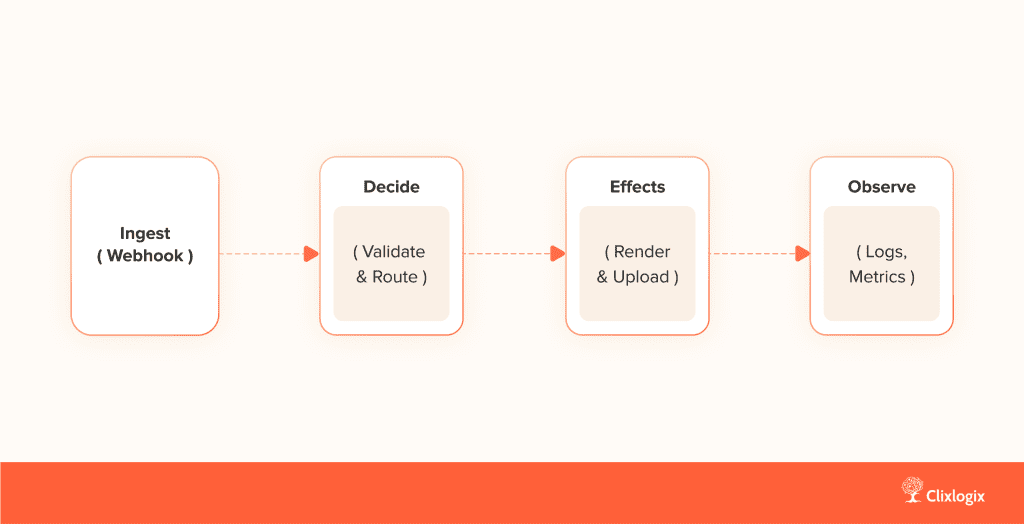
In practice:
Ingest – a form trigger posts a product name and image.
Decide – we validate, normalize, and deduplicate.
Effects – we fan out three render jobs, poll their status, and upload results.
Observe – we log with a consistent envelope and keep a failure story for every terminal error.
System Architecture For Video Creation WorkFlow
[Form Trigger]
↓
[Validate & Normalize] ──→ [DLQ:Policy]
↓
[Persona Generator] → [Prompt Parser]
↓
[Script Generator]
↓
[Frame Composer]
↓
[Render Queue] →→→→→→→→→→→→→→→→ [Nano Banana (Veo) API]
↓
[Polling + Status Check]
↓
[Upload + Metrics] ──→ [DLQ:Render]
↓
[Dashboard / Report]
Why this shape? small responsibilities, explicit error lanes, and asynchronous rendering. n8n carries state; the models do work. The arrows are boring on purpose. Honestly, the first version felt like magic. The fifth felt like software engineering.
Intake & Normalization
Every workflow starts with a form trigger. The system accepts the product name, a single image, and optional metadata. n8n converts the Base64 image into a standard 9:16 portrait frame.
[Form Trigger]
-> [Convert Base64 to Image]
-> [Normalize & Persist]
-> [Policy Gate]
We enforce validation before imagination, aspect ratio, file size, and moderation checks. Anything non-compliant moves to a dead-letter queue (DLQ). The decision is early and cheap.
from PIL import Image
img = Image.open('in.jpg')
canvas = Image.new('RGB',(720,1280),(255,255,255))
offx=(720-img.width)//2; offy=(1280-img.height)//2
canvas.paste(img,(offx,offy))
canvas.save('frame.jpg')Deterministic composition ensures the same input always yields identical framing critical for reproducibility later in rendering.
Persona Generation
The faceless workflow doesn’t rely on actors. Instead, it creates a digital advocate, someone believable who could authentically promote the product. We use Gemini 2.5 Pro for persona synthesis.
Prompt:
// ROLE & GOAL
You are a Casting Director and Consumer Psychologist. Study the product image and write one believable advocate for it.
Only describe the person; do not write ad copy.
// INPUT
Product: {{ $node[‘form_trigger’].json[‘Product Name’] }}
// OUTPUT (JSON)
{
“identity”: {“name”: “<first>”, “age”: <int>, “gender”: “<text>”, “city”: “<plausible>”, “role”: “<occupation>”},
“appearance”: “<distinctive look and clothing shorthand>”,
“personality”: [“adjectives”, “that”, “fit”],
“lifestyle”: “<hobbies, routine, setting>”,
“why_trusted”: “<one sentence rationale>”
}
We hash the persona output and persist it alongside the product metadata. This frozen state forms a unique runId, ensuring future replays remain consistent.
Script Generation (8‑Second Natural Ads)
Each persona produces three short, faceless UGC scripts, each one with a different intent like Excited Discovery, Casual Recommendation, and In‑the‑Moment Demo.
Prompt:
// ROLE
You direct faceless UGC filmed on a phone. It must feel handheld and unsponsored.
// GOAL
Write 3 scripts (Excited Discovery, Casual Recommendation, In the Moment Demo), each ~8 seconds.
// STRUCTURE
[0:00 – 0:02] Immediate hook or mid‑sentence start.
[0:02 – 0:06] Main talking section with natural pause.
[0:06 – 0:08] Wrap up while product stays visible.
// STYLE
Handheld wobble, natural pauses, self‑corrections, filler words, real lighting. Avoid slogans and polish.
Each script follows the 12 frame logic defined by timestamps and camera actions, but condensed to fit Veo’s preferred 8‑second runtime. It ensures consistency across variants. Each feels user-made, yet every beat lands within the system’s limits.
Shot Timing Blueprint

Authenticity Layer
- Verbal – “like”, “literally”, “honestly”, short self‑corrections.
- Visual – handheld movement, occasional overexposure, background life.
- Audio – room echo or ambient noise; no music beds.
- Rule – dialogue ends by the time mark; cut can be abrupt.
Desired effect is to have consistency across variants. Each feels user‑made, yet every beat lands within the system’s limits.
Frame Preparation & Composition
The first frame is a clean portrait of the product. If proportions mismatch, we extend the background with soft letterboxing, never artificial inpainting. This stage acts as the Resize_Image Node in n8n and prepares the reference frame for Nano Banana.
API Requirement
- Veo expects the reference image to match the output resolution exactly (we use 720×1280, 9:16).
- The reference can be used as the last frame or to anchor initial composition; we prefer a simple static reference for determinism.
Design principles revolve around aesthetic uniformity without model unpredictability. The pipeline prefers stability over “wow” moments that break repeatability.
Rendering with Nano Banana (Google Veo)
The n8n orchestrator fans out three render jobs, each using a separate lane.
[Decide & Enqueue] → [Render #1]
→ [Render #2]
→ [Render #3]
Each render calls Nano Banana for short‑form faceless video generation. The API returns a job_id (long‑running operation). We poll for completion every 15 seconds with a maximum of 6 attempts (~90 seconds total).
let done=false; const tries=6; // ~90s
for(let i=0;i<tries;i++){
await $run('wait_15s');
const r=await $run('get_op'); // status: queued | processing | done
if(r.json.done){done=true;break;}
}
if(!done) throw new Error('render_timeout');Failed attempts move to a replayable DLQ. The queue keeps latency predictable even during heavy loads.
Pricing-wise Veo bills by duration. Short clips (4–8s) cost roughly $0.05 to $0.10 per second, varying by model tier and region. We compute cost from configuration and log it per render.
Uploads, Budgets & Observability
Uploads are idempotent. Each key is unique to a (product, image, script) tuple.
const key = `${$json.productHash}_${$json.imageHash}_${$json.scriptIdx}`;
const prior = await kv.get(key);
if (prior?.status === 'uploaded') return prior;
await kv.put(key, { status: 'rendering' });
await kv.put(key, { status: 'uploaded', url: uploaded.url });Metrics are emitted as:
runId, stage, status, timestamp, cost
Grafana turns them into flow charts. The team can read the system’s pulse visually. If mtd_cost crosses the defined budget, mid‑tier lanes pause automatically:
if(metrics.mtd_cost >= $env.BUDGET_USD){$flow.setVariable('kill',true)}Error Taxonomy and Replay Logic
policy_violation -> invalid file/moderation -> DLQ:policy_error
render_timeout -> exceeded patience limit -> DLQ:render_failure
429/downstream -> retry with delay; else DLQ
authorization -> manual escalation
Retry & Budget Map
[Error]
├─ policy_violation ─→ DLQ:policy
├─ render_timeout ─→ DLQ:render
├─ 429/downstream ─→ retry with backoff → DLQ
└─ budget_limit ─→ pause lane (resume next window)
Each DLQ entry carries a replay token. Failures are treated as assets – recoverable, explainable, trackable.
Client Outcome, The Boring Kind of Success
For the eCommerce client, a merch lead now uploads a product photo and walks away. n8n validates, generates personas, scripts, and sends render calls. Videos appear in a shared drive under 10 minutes. Week by week, marketing teams get “authentic” UGC ads at scale without filming a second.
They describe it best: “Our most creative process became the most predictable one.”
Lessons That Outlive the Model
After shipping, what remained was the rhythm:
- Validate early.
- Freeze state before branching.
- Split brain from factory.
- Cap patience.
- Treat cost and failure as feedback, not errors.
That rhythm now shapes other automations we build, from conversational AI agents to dynamic video systems. The names of the models change; the discipline stays.
If your team is exploring how to automate UGC, POV or faceless video creation, we’ve built and deployed these workflows for real brands, from intake form to finished clips, using n8n and Google Veo (Nano Banana). Our engineers can share architecture blueprints, cost controls, and integration patterns that make AI video automation production ready.
Thinking about automating your video content factory?
We help teams productionize their AI workflows using n8n and Google Veo – Schedule a 20‑minute consultation.









